Crypto Mining bad, Data Mining worse
Mark Honeychurch - 1st May 2023
Aleh Tsyvinski is a professor of economics at Yale who has been researching Bitcoin and other cryptocurrencies over the last few years, in a bid to understand where the currencies sit within an economy, and figure out how to use them to make money.
The way that Aleh tells it, a few years ago (in 2018) he made a “comprehensive economic analysis” along with one of his PhD students, Yukun Liu, using “textbook finance tools” to figure out what these newfangled currencies are all about. His conclusions were:
- They have a slightly better risk to reward ratio than stocks.
- They don’t act like stocks, traditional currencies or precious metals.
- Their prices aren’t dictated by mining costs (electricity prices, hardware costs, nonce difficulty, etc)
- They are unlikely to collapse to $0.
When it came to being able to predict the crypto market, in order to know when to buy and sell to make a profit, Aleh had a few tips that he had figured out from his data analysis:
- Invest when its value goes up more than 20% in a week.
- Buy when Google searches and Twitter mentions go up, sell when people search for “Bitcoin hack”.
- You should hold at least 1% of your investment in Bitcoin, up to 6% if you think that crypto will continue to perform as it has historically.
Aleh and Yukun also questioned whether “the returns on the stocks in… industries” are “affected by cryptocurrency”, and concluded that “healthcare and consumer goods industries have significant and positive exposures to Bitcoin returns, while the finance, retail, and wholesale industries have no exposure to Bitcoin at all”, and that “the market perceives Ethereum technology as a potential disruptor in the financial industry”. There are more details in the paper, as well as a later paper from 2019.
What’s happened since their research?
Here are how the three currencies Aleh looked at have fared over the last 5 years, since 2018, courtesy of Google (all prices are in NZD):
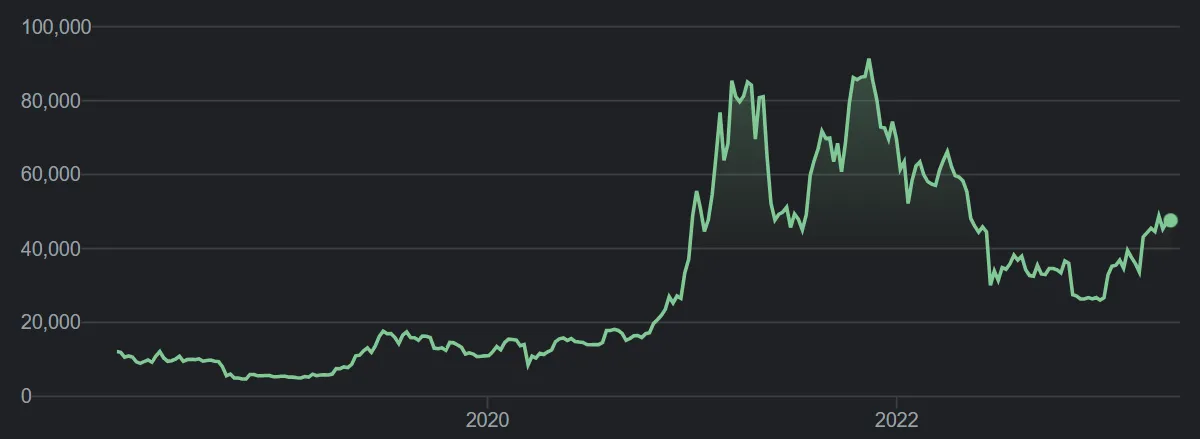
Bitcoin
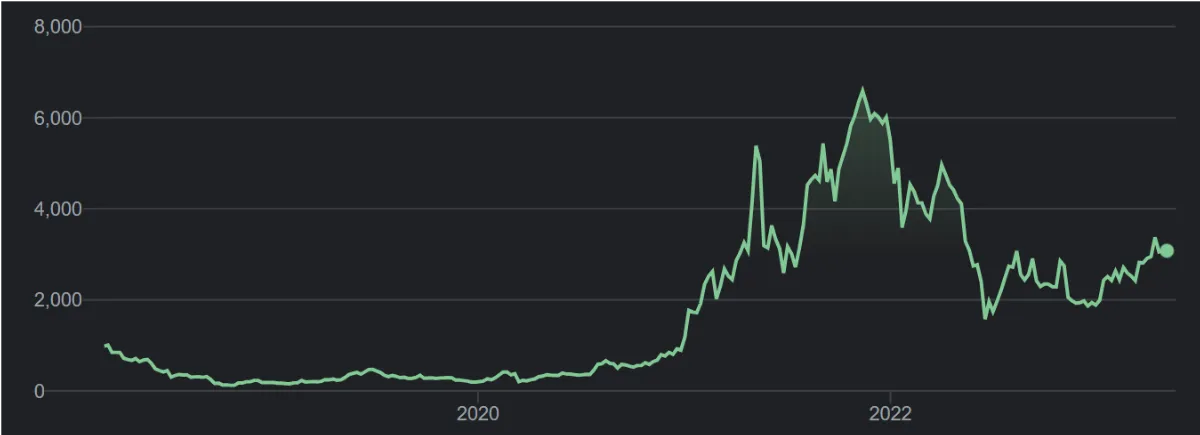
Ethereum
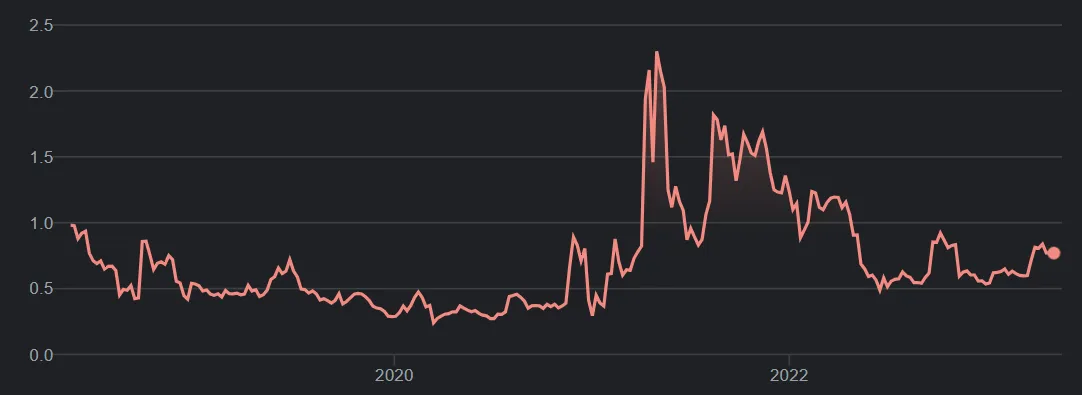
Ripple
Obviously we’ve seen a rapid price increase of all three of these currencies up until late 2021, and then some spectacular crashes (accompanied by major crypto companies going bust, crypto heists, the rise and fall of NFTs, etc).
Just looking at those graphs, it seems to me that some of the larger drops appear to have occurred immediately after a steep rise in price. I wasn’t able to find somewhere that would show me a rolling 7 day percent increase, but I’m guessing some of those rises are more than 20% in a week. I’d feel sorry for anyone who followed Aleh’s advice and bought after these 20% increases at any time within the last 5 years, as they’re likely to have lost at least a portion of their money.
Now, I’m not a financial expert, so beyond this one trite observation (which may not even be accurate) I don’t feel qualified to delve deeply into Aleh’s recommendations and observations. But it’s okay, I don’t need to, as professor Gary Smith from Pomona College has done it in his new book:

Distrust: Big Data, Data-Torturing, and the Assault on Science
Yep, that’s the title of Gary’s book. And if that title hasn’t already tipped you off to what’s coming up in this article, what about the fact that I found out about this book at the Retraction Watch website, which does an amazing job of documenting academic mishaps and fraud. Surely it’s now obvious that we’re about to hear of bad analysis and erroneous conclusions. And yes, it turns out that many of the conclusions Aleh and his co-author came to were definitely erroneous.
The excerpt of the book available on Retraction Watch starts with Aleh’s recommendation to buy when there are searches for “Bitcoin”, and sell when there are searches for “Bitcoin hack”. For this, Aleh and Yukun’s analysis was based on searches made in the previous four weeks and Bitcoin price changes in the following 7 weeks. Gary Smith suggests that these seemingly arbitrary numbers are indicative that the pair of researchers tried many combinations of numbers of weeks going backward and forward, and settled on values that showed a positive correlation. And, of course, many of us know as skeptics, and possibly as readers of the XKCD comic, that it’s not okay to fish for a positive result and then discard your negative results, presenting only the positive case and treating it like it’s statistically significant.

Gary, along with a colleague, Owen Rosebeck, did the sensible thing and tried to apply these correlations forward in time from the data set Aleh and Yukun had used, and unsurprisingly found that the correlations had no predictive power at all - with new data, the variables were no longer closely correlated.
The same thing was found for Twitter posts - the correlations that the authors had found did not continue when applied to fresh data.
When it came to the authors’ conclusion that “healthcare and consumer goods industries have significant and positive exposures to Bitcoin returns”, as well as an apparent negative correlation with the stock returns of fabricated products and metal mining industries, it turns out that this was even more of a fishing expedition. Their methodology was to check for correlations with a whopping 810 other factors, including “the Canadian dollar–U.S. dollar exchange rate, the price of crude oil, and stock returns in the automobile, book, and beer industries”. Looking for patterns in large data sets in this manner is known as data mining, and this particular faux pas of misusing data mining to find spurious correlations is known as data dredging.
As Gary Smith writes in his book:
“The Achilles heel of data mining is that large data sets inevitably contain an enormous number of coincidental correlations that are just fool’s gold in that they are no more useful than correlations among random numbers. Most fortuitous correlations do not hold up with fresh data, though some, coincidentally, will for a while. One statistical relationship that continued to hold during the period they studied and the year afterward was a negative correlation between bitcoin returns and stock returns in the paperboard-containers-and-boxes industry. This is surely serendipitous—and pointless.”
So, what should Aleh and Yukun have done differently? One method of handling this, as we can see above, is to test potential correlations on fresh data. This can either mean watching these chosen variables for a further period of time to see if the correlation holds, or searching for correlations using part of the available data set, e.g. using the first part of the data chronologically (maybe 5 out of 6 years). You can then see if the correlation holds for the portion of the data that wasn’t used in the analysis. This is quicker to do, as you don’t have to wait for the new data to come in after your analysis to test against, but it also means that there’s less data available for your analysis.
For either of these cases, as Gary pointed out in the paragraph above, there’s still a chance that a spurious correlation will continue to match up with fresh data - that’s just the nature of randomness. And, of course, the more correlations you discover and test on new data, the greater the chance that at least one of them will continue to spuriously track with the new data.
There are other, more complex ways of minimising your chances of finding spurious correlations, and you can read about these in the Remedies section of the data dredging Wikipedia page.
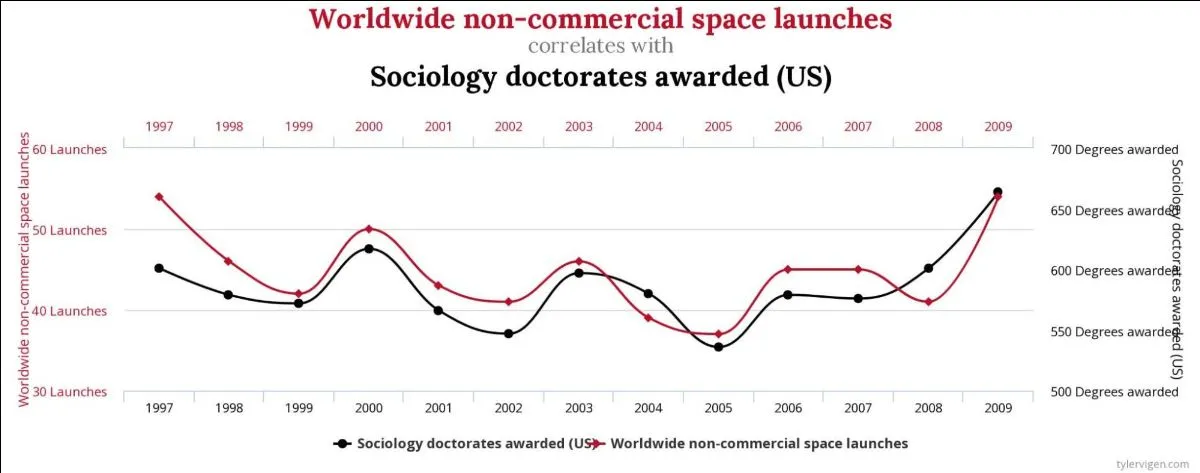
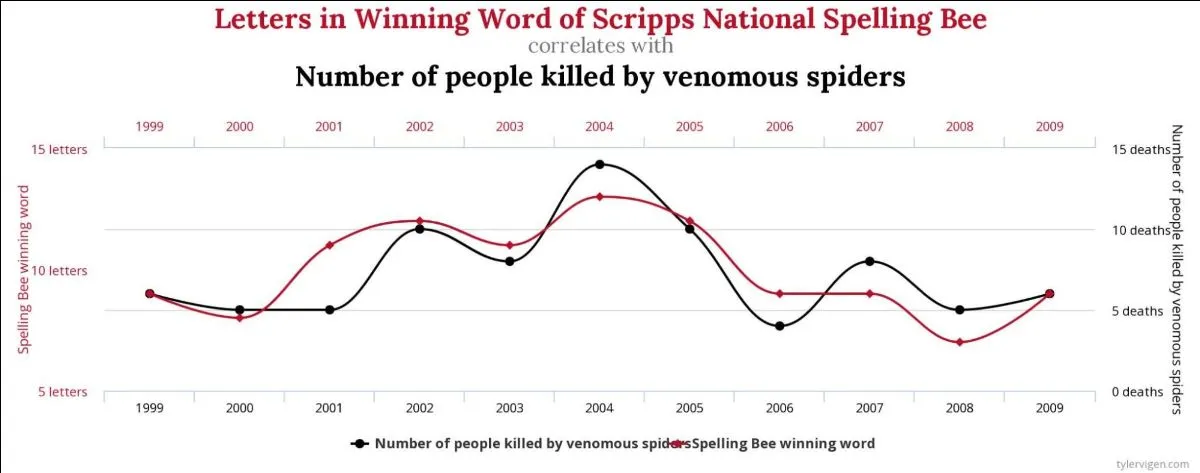
This entire thing puts me in mind of the hugely enjoyable Spurious Correlations website, where you can see pretty graphs of close correlations between sets of obviously unrelated data, such as rocket launches and sociology doctorates, or spelling bee winning word length and people killed by spiders: